AI-Powered Synthetic Data: Safeguarding Personal Information in DWH
Every successful company eventually reaches a point a DWH is needed. And who could be better at building one than a company focused on delivering DWH solutions for various clients, right? But there is always a catch – the data.
The deal is: how do you use real data while staying compliant?
You have a great team of specialists capable of doing it, but the data is mostly private – salaries, costs, projects, personal data, etc. That’s something you simply cannot give to anyone to build your solution.
If you want to leverage your internal capacities on a larger scale, you need to ensure the data is safe to use in development. Basically, you either create dummy data to reflect all the dependencies and needs, or you can synthesize it.
That’s what I will focus on in this article.
For a long time, we hoped for an environment where people could try new technologies and learn with some added value.
Not just creating the fifth test DWH from the AdventureWorks DB source.
However, the nature of our data often goes against using it for these purposes.
This is where we met SynData and learned about smart and easy ways of creating synthetic data at a large scale.
Their engine, Synapp, creates a mirror of the schema of the original data (maintaining relations between tables) and populates it with synthetic data.
POC Powered by Generative AI
So, we tried it right on our POC. We took our internal data – personal details, work logs, allocations, sales, and much more – basically the data you want to keep only for a certain group of people, and we used it as a source for creation of synthetic data that we can freely use for our internal purposes.
This way, anyone can see or develop on top of the synthetic data because it’s not the real data, but it has the same structure, behavior, and very similar statistical distribution, allowing you to build your solution on it. Then you can move it to production where the real data sits, and it should work without issue.
What is synthetic data? Synthetic data has the same statistical distribution and correlations as the original data but is anonymized. Applications vary, including testing environments, analytics, and sharing data while preserving data privacy.
In the background, Synapp trains a deep learning algorithm called CTGAN on the original data. Once the training phase is finished, the resulting generator can start generating synthetic data, producing as many data points as requested. Synthetic data is Generative AI.
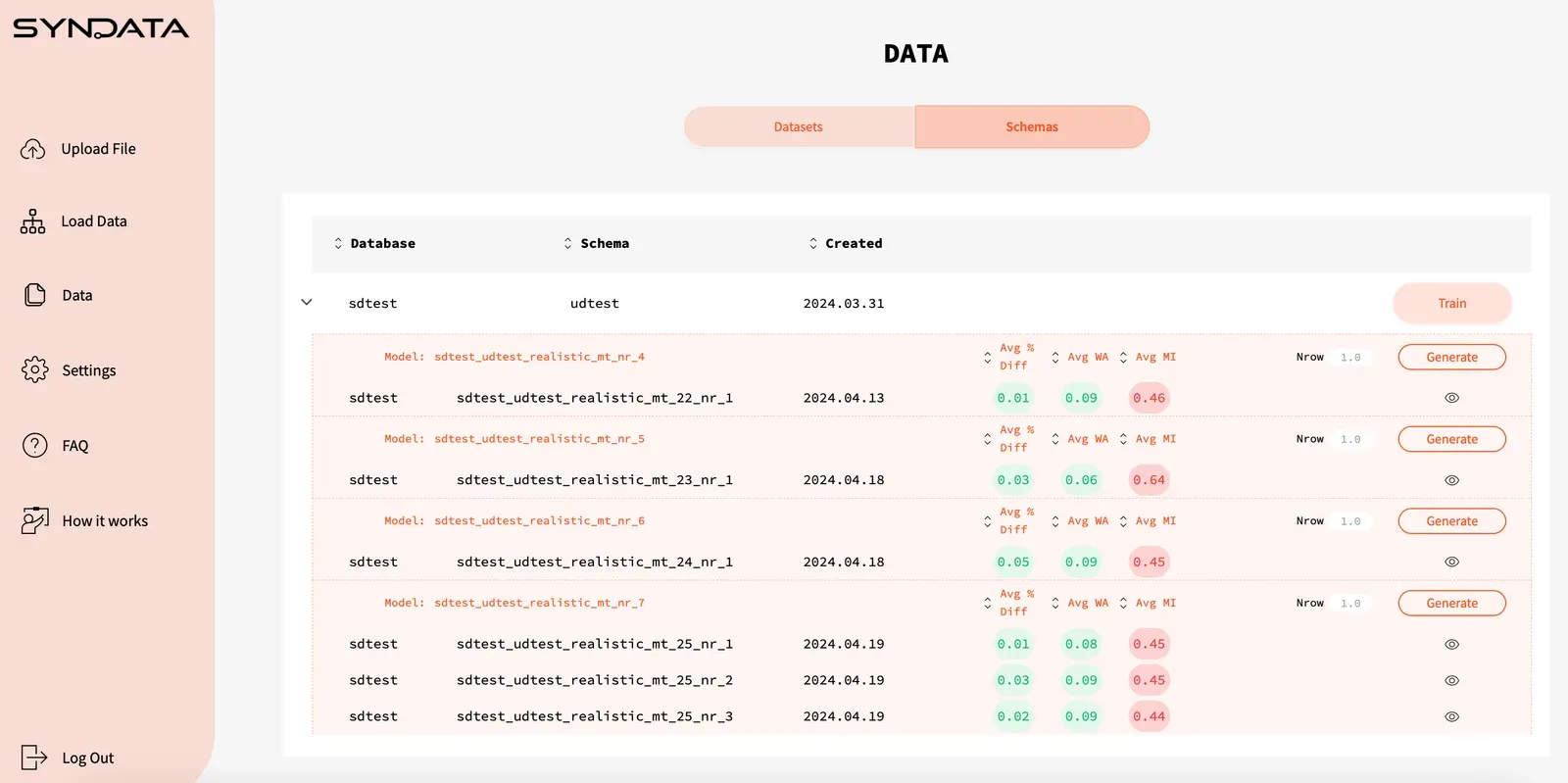
I used Synapp, where in a few clicks I connected to our PostgreSQL database. There you can choose if you want to synthesize data from one table or a schema and can tweak the synthesization process to your needs.
We went with the schema option because the connections between the tables were crucial for our use case. From there, you basically train a model that generates data for you. Synapp will then create a table or schema in your defined database with the synthetic results.
A nice thing is that you can easily choose the size of the output. Do you need a small fraction of the data for quick tests? You got it. Or maybe you need large test sets for performance tests. No problem, it can be generated as well with just a few clicks.

Easy Way to Streamline Your Development
After a few tries (six to be precise), we were satisfied with the quality of the result set and moved on with the solution development.
Even though our use case involved relatively small data sets (a few hundred rows in some tables), all results were usable. And as we know, machine learning improves with larger volumes, so having usable results even with small datasets is promising.
The last step before using the data was just moving them to the proper destination. This can be avoided by setting up the correct target location within Synapp. But since it was just a POC, I had the data on a completely separate machine to conduct these tests.
After having the synthesized data in development, the process is the same as with real data. It is human-readable; the data makes sense, and you can develop whatever you want.
We did a basic star schema design on top of this data, followed by a few PowerBI reports.
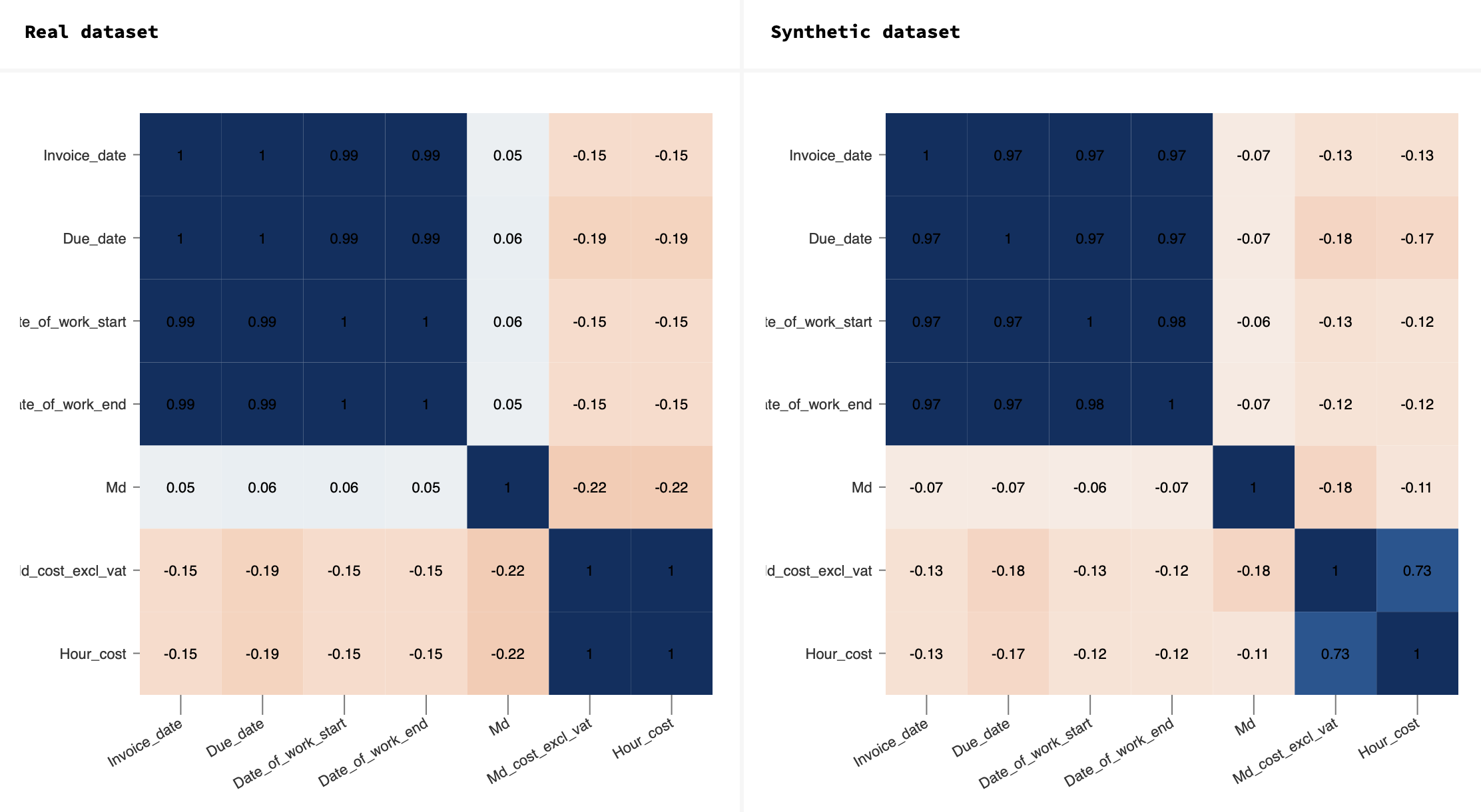
Working with it felt really good. Of course, you can see that it’s synthetic data, but all of it is linked, and you can see their values, not just some hash strings that could be random data.
Conclusion: A New Way of Data Anonymization That Makes Sense
To wrap it up, synthetic data and Synapp have many different use cases. One significant advantage is that it allows you to use your internal data and develop solutions in a safe access mode for everyone involved. The only thing you need to consider is that to have high-quality synthetic data, you need a person who understands statistics and data generation to determine the necessary parameters for your generated datasets.
Obtaining our development data this way was super easy, and in the end, quite fast. The biggest time effort was on the legal side, not the technical one. It was intuitive, and the results allowed us to proceed directly to development.
Our POC proved that synthetic data can be used even in smaller environments, and its benefits are clear.
Synthetic data can be intimidating because it’s new and sounds complex.
However, having an easy-to-use engine like Synapp proves that synthetic data has more advantages than generating test data manually or masking (anonymizing) the original data.

